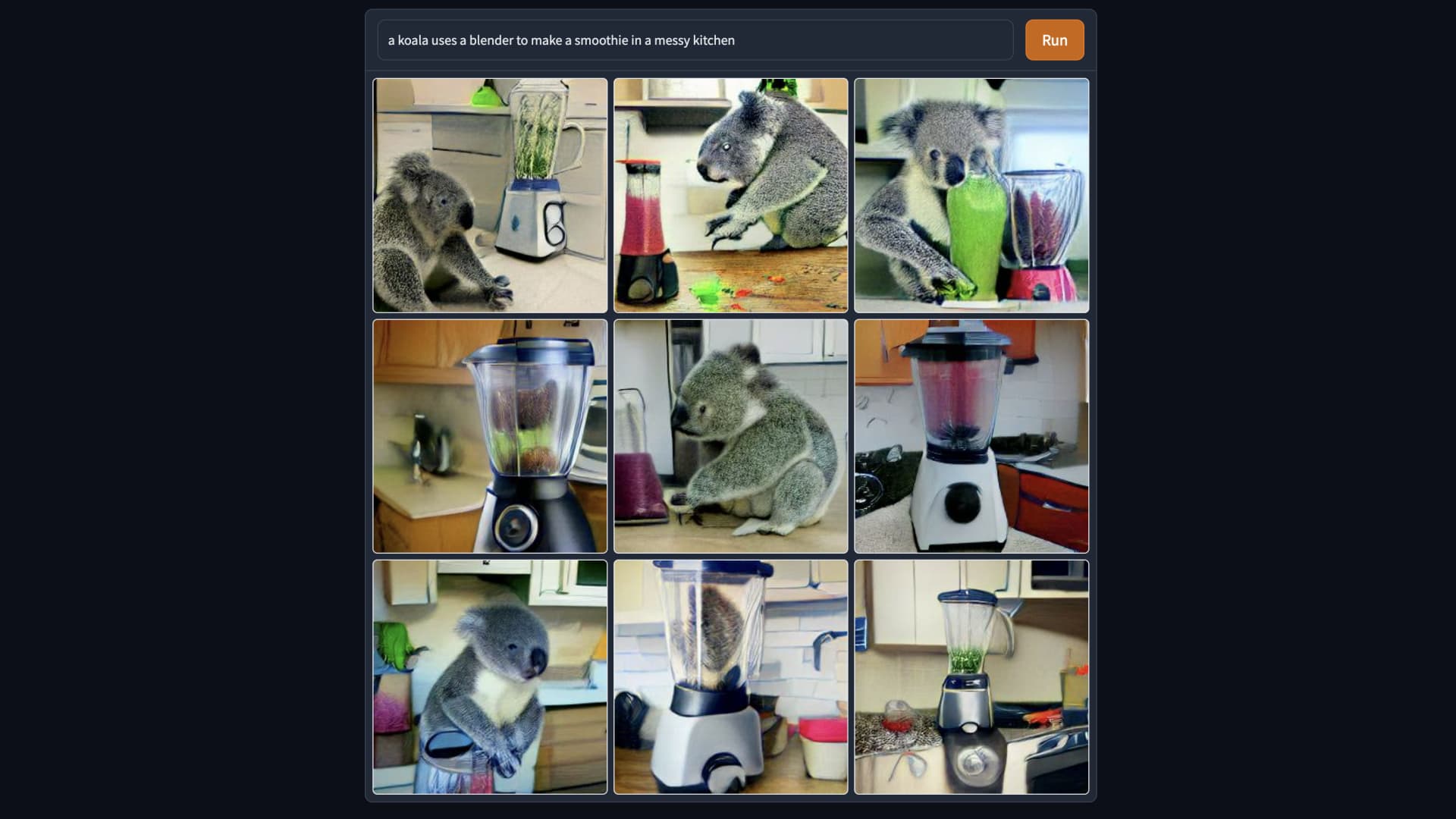
In scrolling through your social media feeds of late, there’s a good chance you’ve noticed illustrations accompanied by captions. They’re popular now.
The pictures you’re seeing are likely made possible by a text-to-image program called DALL-E. Before posting the illustrations, people are inserting words, which are then being converted into images through artificial intelligence models.
For example, a Twitter user posted a tweet with the text, “To be or not to be, rabbi holding avocado, marble sculpture.” The attached picture, which is quite elegant, shows a marble statue of a bearded man in a robe and a bowler hat, grasping an avocado.
The AI models come from Google’s Imagen software as well as OpenAI, a start-up backed by Microsoft that developed DALL-E 2. On its website, OpenAI calls DALL-E 2 “a new AI system that can create realistic images and art from a description in natural language.”
But most of what’s happening in this area is coming from a relatively small group of people sharing their pictures and, in some cases, generating high engagement. That’s because Google and OpenAI have not made the technology broadly available to the public.
Many of OpenAI’s early users are friends and relatives of employees. If you’re seeking access, you have to join a waiting list and indicate if you’re a professional artist, developer, academic researcher, journalist or online creator.
“We’re working hard to accelerate access, but it’s likely to take some time until we get to everyone; as of June 15 we have invited 10,217 people to try DALL-E,” OpenAI’s Joanne Jang wrote on a help page on the company’s website.
One system that is publicly available is DALL-E Mini. it draws on open-source code from a loosely organized team of developers and is often overloaded with demand. Attempts to use it can be greeted with a dialog box that says “Too much traffic, please try again.”
It’s a bit reminiscent of Google’s Gmail service, which lured people with unlimited email storage space in 2004. Early adopters could get in by invitation only at first, leaving millions to wait. Now Gmail is one of the most popular email services in the world.
Creating images out of text may never be as ubiquitous as email. But the technology is certainly having a moment, and part of its appeal is in the exclusivity.
Private research lab Midjourney requires people to fill out a form if they wish to experiment with its image-generation bot from a channel on the Discord chat app. Only a select group of people are using Imagen and posting pictures from it.
The text-to-picture services are sophisticated, identifying the most important parts of a user’s prompts and then guessing the best way to illustrate those terms. Google trained its Imagen model with hundreds of its in-house AI chips on 460 million internal image-text pairs, in addition to outside data.
The interfaces are simple. There’s generally a text box, a button to start the generation process and an area below to display images. To indicate the source, Google and OpenAI add watermarks in the bottom right corner of images from DALL-E 2 and Imagen.
The companies and groups building the software are justifiably concerned about having everyone storming the gates at once. Handling web requests to execute queries with these AI models can get expensive. More importantly, the models aren’t perfect and don’t always produce results that accurately represent the world.
Engineers trained the models on extensive collections of words and pictures from the web, including photos people posted on Flickr.
OpenAI, which is based in San Francisco, recognizes the potential for harm that could come from a model that learned how to make images by essentially scouring the web. To try and address the risk, employees removed violent content from training data, and there are filters that stop DALL-E 2 from generating images if users submit prompts that might violate company policy against nudity, violence, conspiracies or political content.
“There’s an ongoing process of improving the safety of these systems,” said Prafulla Dhariwal, an OpenAI research scientist.
Biases in the results are also important to understand, and represent a broader concern for AI. Boris Dayma, a developer from Texas, and others who worked on DALL-E Mini spelled out the problem in an explanation of their software.
“Occupations demonstrating higher levels of education (such as engineers, doctors or scientists) or high physical labor (such as in the construction industry) are mostly represented by white men,” they wrote. “In contrast, nurses, secretaries or assistants are typically women, often white as well.”
Google described similar shortcomings of its Imagen model in an academic paper.
Despite the risks, OpenAI is excited about the types of things that the technology can enable. Dhariwal said it could open up creative opportunities for individuals and could help with commercial applications for interior design or dressing up websites.
Results should continue to improve over time. DALL-E 2, which was introduced in April, spits out more realistic images than the initial version that OpenAI announced last year, and the company’s text-generation model, GPT, has become more sophisticated with each generation.
“You can expect that to happen for a lot of these systems,” Dhariwal said.
WATCH: Former Pres. Obama takes on disinformation, says it could get worse with AI


















