Somehow, Microsoft Build, the software company, and cloud provider’s annual developer conference is back. Now even the virtual nature of the event is an annual tradition — though I hope one we can abandon next year. But one tradition not abandoned is using the occasion of Build to announce new developments on the data and analytics front. This year, while Microsoft has no groundbreaking news per se, it has an impressive roster of announcements around new features and new service tiers for its BI and database offerings in the cloud.
Streaming data and aggregations, powering through
Let’s start with Microsoft’s Power BI announcements. These include the ability for Power BI dataflows (the cloud-based incarnation of Power Query) to handle streaming data sources, starting with Azure IoT Hub and Azure Event Hubs. I haven’t been hands-on with this feature at all yet, but the team promises it will make streaming data and real-time analytics as accessible as batch data and conventional analytics is now, not just for BI specialists and data engineers, but for business users. And since Event Hubs can work in an Apache Kafka-compatible mode, it begs the question of whether this feature will one day work with that open-source streaming event platform.
Also of interest is a feature called automatic aggregations. To appreciate this feature you have to know about the basic aggregations feature that underlies it. The basic feature lets you pre-calculate aggregations on your measures, making for superior performance, especially against data sources for which Power BI is connected over DirectQuery, which fetches data from the back-end data source.
With aggregations, Power BI can avoid going all the way to the back-end for common summarized data, and reserve that approach instead for relatively small sets of detail data. The problem with aggregations is that they have to be designed when a user models the data Power BI will be querying. And the good news here is that the automatic aggregations feature will build these automatically, based on actual observed query patterns, with an algorithm that gets better as it collects more such observations.
The previews of both streaming dataflows and automatic aggregations are coming in July, and both will be exclusive to Power BI Premium. Since Premium is now available on a per-user basis for an extra $10 per month over Power BI Pro, that keeps these features relevant to more customers. Meanwhile, another Premium feature, Power BI deployment pipelines, is getting developer-oriented Automation APIs that enable tools such as Azure DevOps, GitHub, and Azure Pipelines to automate the deployment of Power BI assets. Automation APIs are available now.
That’s a lot of Premium-only features, and the Premium-Per-User pricing tier may mean we’ll see more of them. Meanwhile, Microsoft is releasing a very cool new feature that allows Power BI reports to be embedded in Jupyter notebooks, as an open-source Python package. And it’s compatible with Power BI Pro, including the version available as a free trial. An image of a Power BI-infused Jupyter notebook appears below.
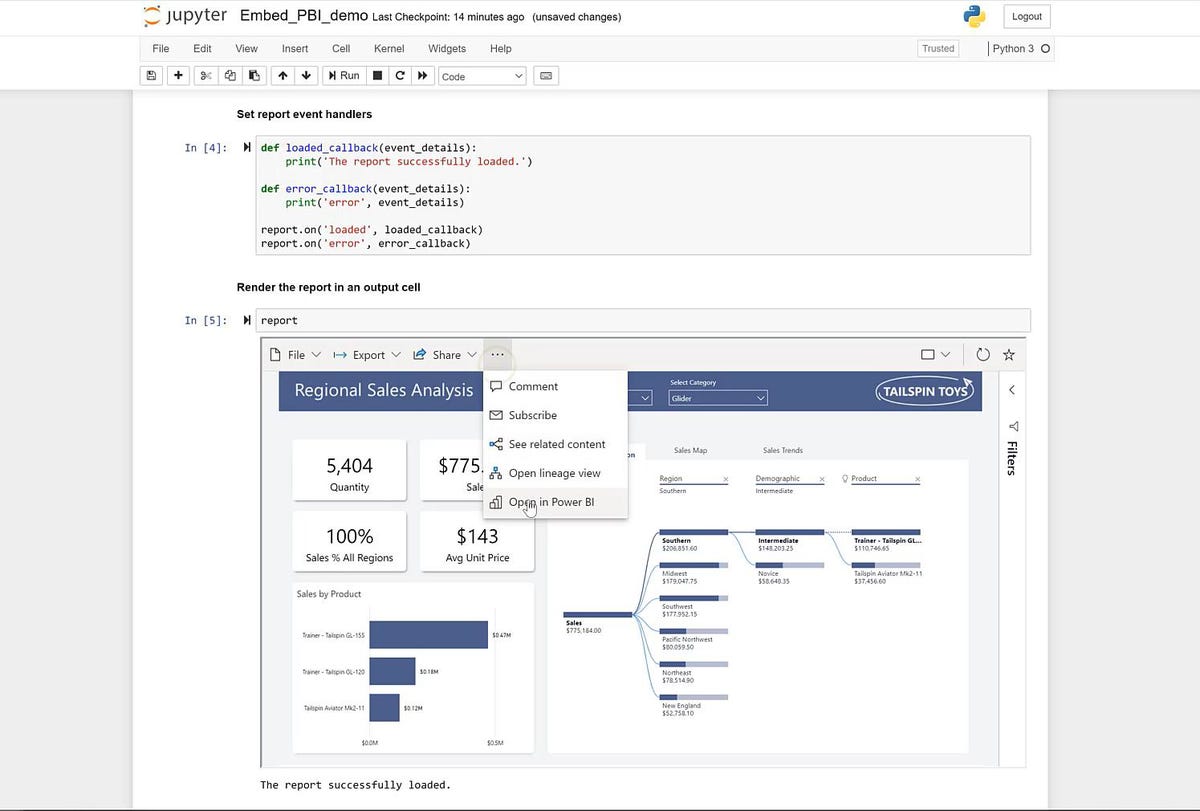
A Power BI report embedded in a Jupyter notebook.
Credit: Microsoft
Cosmos DB: Serverless, cached, encrypted, and free(r)
On the database side of the world, Microsoft has a lot of news around Cosmos DB, and some miscellaneous bits for MySQL and Postgres.
To start, Cosmos DB, which is Microsoft’s managed, high-scale, multi-model NoSQL database is taking its cloud-native pedigree one step further, by bringing its serverless option into general availability, for all of Cosmos’ many APIs. A serverless version of Cosmos DB allows customers to use it without needing to provision explicitly-sized clusters, making it work well for what Microsoft calls “spiky traffic patterns.” Even for customers comfortable with cluster sizing, the serverless option will essentially provide zero-maintenance auto-sizing. The credo of serverless, after all, is to delegate to the service the responsibility of dispensing the resources you need, when you need them.
Cosmos is also getting a bunch of features that old-time relational database professionals can appreciate. These include an integrated cache, role-based access controls (RBAC), and Always Encrypted, a feature borrowed from SQL Server and Azure SQL Database that fully encrypts data within an application before it’s even saved in the database. The integrated cache service is particularly interesting because it doesn’t just increase performance, it saves money, ostensibly by reducing full database reads. Microsoft says the cache cuts costs and boosts performance for read-heavy workloads by up to 96 percent and 300 percent, respectively.
Cosmos DB is also expanding its free tier. The new offering provides developers 1,000 RU/s (request units per second) provisioned throughput and 25GB free storage, monthly. And speaking of free, Microsoft has, for some time now, offered a Cosmos DB emulator, that allows developers to run their code against a working Cosmos DB instance, without incurring charges for the cloud service. The catch was that emulator only worked on Windows machines, but Microsoft is today announcing a Linux version of the emulator, that also runs on Macs. Like Cosmos DB Serverless, the expanded free tier is generally available, as is RBAC; meanwhile, the integrated cache, Always Encrypted and the Linux emulator are in preview.
OSS RDBMS, PDQ
Back in the world of relational databases, a free 12-month offer for Azure Database for PostgreSQL and Azure Database for MySQL Flexible Server, available in June, will offer up to 750 hours a month free for the first 12 months with an Azure free account. In addition, for Azure Database for PostgreSQL – Hyperscale (Citus), a new basic tier, in preview, will offer entry-level capabilities, based on a single node deployment. While anything called “hyperscale” that’s based on a single node seems anomalous to say the least, it’s probably best to think of this in the same manner as Cosmos DB’s emulator — as a working endpoint for developing and testing code. The difference is that it can be productionalized in-place, as Microsoft offers the option to add worker nodes and scale up afterward.
Sometimes Build is used by product teams to launch major new versions or releases of a product. At other times, it’s used as a convenient launch timeframe for smaller features. In the world of data, this year’s Build seems to be a case of the latter, but when you roll all the small bits up, it results in a significant number of new features and capabilities. Sometimes, that’s the best way to go.
Microsoft is a customer of Brust’s advisory firm, Blue Badge Insights. He is also a Microsoft Data Platform MVP.

