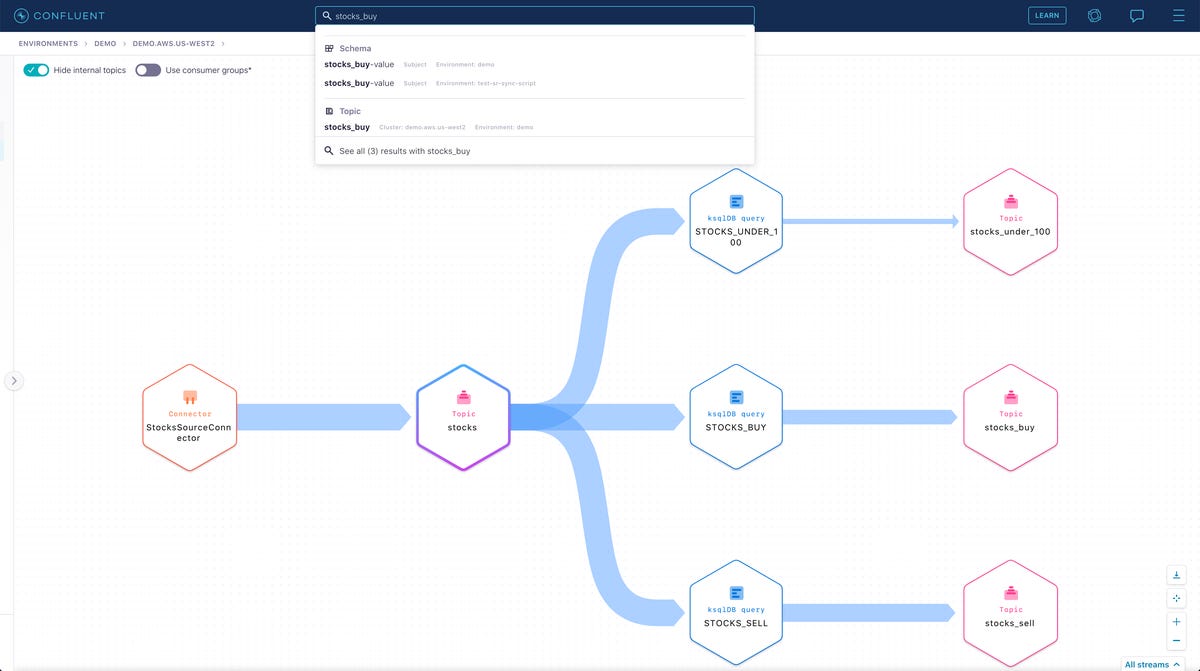
A Confluent Stream Governance lineage map tracing the source of Kafka topic content from a data connector, a source Kafka topic, and several ksqlDB queries.
Credit: ConfluentAt the Kafka Summit virtual conference today, the event’s sponsor and company founded by Apache Kafka‘s creators, Confluent, is announcing its new Stream Governance suite for the governing of real-time, streaming data. The managed cloud service is, according to the company, the first such solution on the market, and aims to bring governance and protection to data-in-motion comparable to what has become standard for data-at-rest.
Goals and pillars
ZDNet spoke with Confluent’s co-founder and CEO, Jay Kreps, who explained that Stream Governance targets modern organizations’ two biggest concerns when it comes to data: how to unlock it all and yet do it in a way that’s safe, secure and in compliance with industrial and regulatory data protection frameworks that continue to increase in number.
Stream Governance concentrates on three pillars: the discoverability, traceability and quality of data. The suite does so through its stream catalog, stream lineage (pictured in the screenshot at the top of this post) and stream quality components, respectively. Confluent’s Kreps made the point that, because of the way data streaming works, governing it can be done largely on an automated basis. With the data volumes prevalent today, that’s a welcome fact.
By popular demand
Kreps asserted to ZDNet that a large number of governance needs come from when data moves, yet most mainstream data governance and data catalog solutions focus on data-at-rest. Confluent’s goal is to bridge that gap and do so in a way that integrates with those very mainstream platforms. In other words, Stream Governance is focused on establishing trust in the real-time data moving throughout a business, and isn’t trying to displace existing commercial and open source data governance platforms, frameworks and standards.
Kreps says Stream Governance’s feature set is 100% driven by customer demand, itself catalyzed by the EU’s General Data Protection Regulation (GDPR), California’s Consumer Protection Act (CCPA) and other certifications and regulations, both existing and emerging. Also stoking customer demand are the mainstream growth in data volumes and increasing use cases for digital business transformation.
Wider horizons?
Although Confluent intends to keep Stream Governance focused on streaming data, at certain organizations, that scope may not be a narrow one. Confluent has previously announced technologies such as “Infinite Storage” in its Confluent Cloud platform, which allows Kafka topics to serve as persistent data repositories, rather than just roadways for data transiting through. With that in mind, Stream Governance’s scope of influence could be wide indeed, and so could the notion that all datasets can be seen as special instances of data streams.
Also read: Confluent announces Infinite Storage for Apache Kafka
No matter what, leaving data streams ungoverned, with hindsight, is a bit like leaving a special purpose computer unprotected by a firewall. It’s imprudent, unsafe and unhygienic. Governing streaming data is welcome support for the notion that all data must be tracked and protected while, at the same time, curated, open and available, in a managed context.


















