- Facebook AI is introducing M2M-100, the first multilingual machine translation (MMT) model that can translate between any pair of 100 languages without relying on English data. It’s open sourced here.
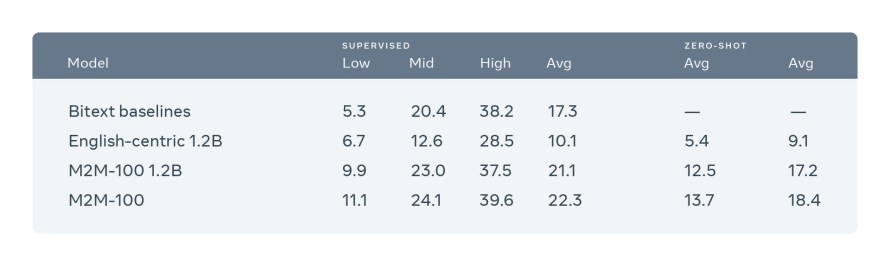
- When translating, say, Chinese to French, most English-centric multilingual models train on Chinese to English and English to French, because English training data is the most widely available. Our model directly trains on Chinese to French data to better preserve meaning. It outperforms English-centric systems by 10 points on the widely used BLEU metric for evaluating machine translations.
- M2M-100 is trained on a total of 2,200 language directions — or 10x more than previous best, English-centric multilingual models. Deploying M2M-100 will improve the quality of translations for billions of people, especially those that speak low-resource languages.
- This milestone is a culmination of years of Facebook AI’s foundational work in machine translation. Today, we’re sharing details on how we built a more diverse MMT training data set and model for 100 languages. We’re also releasing the model, training, and evaluation setup to help other researchers reproduce and further advance multilingual models.
Breaking language barriers through machine translation (MT) is one of the most important ways to bring people together, provide authoritative information on COVID-19, and keep them safe from harmful content. Today, we power an average of 20 billion translations every day on Facebook News Feed, thanks to our recent developments in low-resource machine translation and recent advances for evaluating translation quality.
Typical MT systems require building separate AI models for each language and each task, but this approach doesn’t scale effectively on Facebook, where people post content in more than 160 languages across billions of posts. Advanced multilingual systems can process multiple languages at once, but compromise on accuracy by relying on English data to bridge the gap between the source and target languages. We need one multilingual machine translation (MMT) model that can translate any language to better serve our community, nearly two-thirds of which use a language other than English.
In a culmination of many years of MT research at Facebook, we’re excited to announce a major milestone: the first single massively MMT model that can directly translate 100×100 languages in any direction without relying on only English-centric data. Our single multilingual model performs as well as traditional bilingual models and achieved a 10 BLEU point improvement over English-centric multilingual models.
Using novel mining strategies to create translation data, we built the first truly “many-to-many” data set with 7.5 billion sentences for 100 languages. We used several scaling techniques to build a universal model with 15 billion parameters, which captures information from related languages and reflects a more diverse script of languages and morphology. We’re open-sourcing this work here.
Mining Hundreds of Millions of Sentences for Thousands of Language Directions
One of the biggest hurdles of building a many-to-many MMT model is curating large volumes of quality sentence pairs (also known as parallel sentences) for arbitrary translation directions not involving English. It’s a lot easier to find translations for Chinese to English and English to French, than, say, French to Chinese. What’s more, the volume of data required for training grows quadratically with the number of languages that we support. For instance, if we need 10M sentence pairs for each direction, then we need to mine 1B sentence pairs for 10 languages and 100B sentence pairs for 100 languages.
We took on this ambitious challenge of building the most diverse many-to-many MMT data set to date: 7.5 billion sentence pairs across 100 languages. This was possible by combining complementary data mining resources that have been years in the making, including ccAligned, ccMatrix, and LASER. As part of this effort, we created a new LASER 2.0 and improved fastText language identification, which improves the quality of mining and includes open sourced training and evaluation scripts. All of our data mining resources leverage publicly available data and are open sourced.
Facebook AI’s new many-to-many multilingual model is a culmination of several years of pioneering work in MT across breakthrough models, data mining resources, and optimization techniques. This timeline highlights a few noteworthy achievements. Additionally, we created our massive training data set by mining ccNET, which builds on fastText, our pioneering work on processing word representations; our LASER library for CCMatrix, which embeds sentences in a multilingual embedding space; and CCAligned, our method for aligning documents based on URL matches. As part of this effort, we created LASER 2.0, which improves upon previous results.
Still, even with advanced underlying technologies like LASER 2.0, mining large-scale training data for arbitrary pairs of 100 different languages (or 4,450 possible language pairs) is highly computationally intensive. To make this type of scale of mining more manageable, we focused first on languages with the most translation requests. Consequently, we prioritized mining directions with the highest quality data and largest quantity of data. We avoided directions for which translation need is statistically rare, like Icelandic-Nepali or Sinhala-Javanese.
Next, we introduced a new bridge mining strategy, in which we group languages into 14 language groups based on linguistic classification, geography, and cultural similarities. People living in countries with languages of the same family tend to communicate more often and would benefit from high-quality translations. For instance, one group would include languages spoken in India, like Bengali, Hindi, Marathi, Nepali, Tamil, and Urdu. We systematically mined all possible language pairs within each group.
To connect the languages of different groups, we identified a small number of bridge languages, which are usually one to three major languages of each group. In the example above, Hindi, Bengali, and Tamil would be bridge languages for Indo-Aryan languages. We then mined parallel training data for all possible combinations of these bridge languages. Using this technique, our training data set ended up with 7.5 billion parallel sentences of data, corresponding to 2,200 directions. Since the mined data can be used to train two directions of a given language pair (e.g., en->fr and fr->en), our mining strategy helps us effectively sparsely mine to best cover all 100×100 (a total of 9,900) directions in one model.
To supplement the parallel data for low-resource languages with low translation quality, we used the popular method of back-translation, which helped us win first place at the 2018 and 2019 WMT International Machine Translation competitions. If our goal is to train a Chinese-to-French translation model, for instance, we’d first train a model for French to Chinese and translate all of the monolingual French data to create synthetic, back-translated Chinese. We’ve found that this method is particularly effective at large scale, when translating hundreds of millions of monolingual sentences into parallel data sets. In our research setting, we used back-translation to supplement the training of directions we had already mined, adding the synthetic back-translated data to the mined parallel data. And we used back-translation to create data for previously unsupervised directions.
Overall, the combination of our bridge strategy and back-translated data improved performance on the 100 back-translated directions by 1.7 BLEU on average compared with training on mined data alone. With a more robust, efficient, high-quality training set, we were well equipped with a strong foundation for building and scaling our many-to-many model.
We also found impressive results on zero-shot settings, in which there’s no training data available for a pair of languages. For instance, if a model is trained on French-English and German-Swedish, we can zero-shot translate between French and Swedish. In settings where our many-to-many model must zero-shot the translation between non-English directions, it was substantially better than English-centric multilingual models.
Scaling Our MMT Model to 15 Billion Parameters with High Speed and Quality
One challenge in multilingual translation is that a singular model must capture information in many different languages and diverse scripts. To address this, we saw a clear benefit of scaling the capacity of our model and adding language-specific parameters. Scaling the model size is helpful particularly for high-resource language pairs because they have the most data to train the additional model capacity. Ultimately, we saw an average improvement of 1.2 BLEU averaged across all language directions when densely scaling the model size to 12 billion parameters, after which there were diminishing returns from densely scaling further. The combination of dense scaling and language-specific sparse parameters (3.2 billion) enabled us to create an even better model, with 15 billion parameters.
To grow our model size, we increased the number of layers in our Transformer networks as well as the width of each layer. We found that large models converge quickly and train with high data efficiency. Notably, this many-to-many system is the first to leverage Fairscale, the new PyTorch library specifically designed to support pipeline and tensor parallelism. We built this general infrastructure to accommodate large-scale models that don’t fit on a single GPU through model parallelism into Fairscale. We built on top of the ZeRO optimizer, intra-layer model parallelism, and pipeline model parallelism to train large-scale models.
But it’s not enough to simply scale the models to billions of parameters. In order to be able to productionize this model in the future, we need to scale models as efficiently as possible with high-speed training. For example, much existing work uses multimodel ensembling, where multiple models are trained and applied to the same source sentence to produce a translation. To reduce complexity and compute required to train multiple models, we explored multisource self-ensembling, which translates a source sentence in multiple languages to improve translation quality. Also, we built on our work with LayerDrop and Depth-Adaptive, to jointly train a model with a common trunk and different sets of language-specific parameters. This approach is great for many-to-many models because it offers a natural way to split parts of a model by language pairs or language families. By combining dense scaling of model capacity with language-specific parameters (3B in total), we provide the benefits of large models as well as the ability to learn specialized layers for different languages.
On the Path Toward One Multilingual Model for All
For years, AI researchers have been working toward building a single universal model that can understand all languages across different tasks. A single model that supports all languages, dialects, and modalities will help us better serve more people, keep translations up to date, and create new experiences for billions of people equally. This work brings us closer to this goal.
As part of this effort, we’ve seen incredibly fast-paced progress in pretrained language models, fine-tuning, and self-supervision techniques. This collective research can further advance how our system understands text for low-resource languages using unlabeled data. For instance, XLM-R is our powerful multilingual model that can learn from data in one language and then execute a task in 100 languages with state-of-the-art accuracy. mBART is one of the first methods for pretraining a complete model for BART tasks across many languages. And most recently, our new self-supervised approach, CRISS, uses unlabeled data from many different languages to mine parallel sentences across languages and train new, better multilingual models in an iterative way.
We’ll continue to improve our model by incorporating such cutting-edge research, exploring ways to deploy MT systems responsibly, and creating the more specialized computation architectures necessary to bring this to production.

