Every branch of science is increasingly reliant on big data sets and analysis, which means a growing confusion of formats and platforms — more than inconvenient, this can hinder the process of peer review and replication of research. Code Ocean hopes to make it easier for scientists to collaborate by making a flexible, shareable format and platform for any and all datasets and methods, and it has raised a total of $21M to build it out.
Certainly there’s an air of “Too many options? Try this one!” to this (and here’s the requisite relevant XKCD). But Code Ocean isn’t creating a competitor to successful tools like Jupyter or Gitlab or Docker — it’s more of a small-scale container platform that lets you wrap up all the necessary components of your data and analysis in an easily shared format, whatever platform they live on natively.
The trouble appears when you need to share what you’re doing with another researcher, whether they’re on the bench next to you or at a university across the country. It’s important for replication purposes that data analysis — just like any other scientific technique — be done exactly the same way. But there’s no guarantee that your colleague will use the same structures, formats, notation, labels, and so on.
That doesn’t mean it’s impossible to share your work, but it does add a lot of extra steps as would-be replicators or iterators check and double check that all the methods are the same, that the same versions of the same tools are being used in the same order, with the same settings, and so on. A tiny inconsistency can have major repercussions down the road.
Turns out this problem is similar in a way to how many cloud services are spun up. Software deployments can be as finicky as scientific experiments, and one solution to this is containers, which like tiny virtual machines include everything needed to accomplish a computing task, in a portable format compatible with many different setups. The idea is a natural one to transfer to the research world, where you can tie up the data, the software used, and the specific techniques and processes used to reach a given result all in one tidy package. That, at least, is the pitch Code Ocean offers for its platform and “Compute Capsules.”

Say you’re a microbiologist looking at the effectiveness of a promising compound on certain muscle cells. You’re working in R, writing in RStudio on a Ubuntu machine, and your data are such and such collected during an in vitro observation. While you would naturally declare all this when you publish, there’s no guarantee anyone has an Ubuntu laptop with a working Rstudio setup around, so even if you provide all the code it might be for nothing.
If however you put it on Code Ocean, like this, it makes all the relevant code available, and capable of being inspected and run unmodified with a click, or being fiddled with if a colleague is wondering about a certain piece. It works through a single link and web app, cross platform, and can even be embedded on a webpage like a document or video. (I’m going to try to do that below, but our backend is a little finicky. The capsule itself is here.)
More than that, though, the Compute Capsule can be repurposed by others with new data and modifications. Maybe the technique you put online is a general purpose RNA sequence analysis tool that works as long as you feed it properly formatted data, and that’s something others would have had to code from scratch in order to take advantage of some platforms.
Well, they can just clone your capsule, run it with their own data, and get their own results in addition to verifying your own. This can be done via the Code Ocean website or just by downloading a zip file of the whole thing and getting it running on their own computer, if they happen to have a compatible setup. A few more example capsules can be found here.
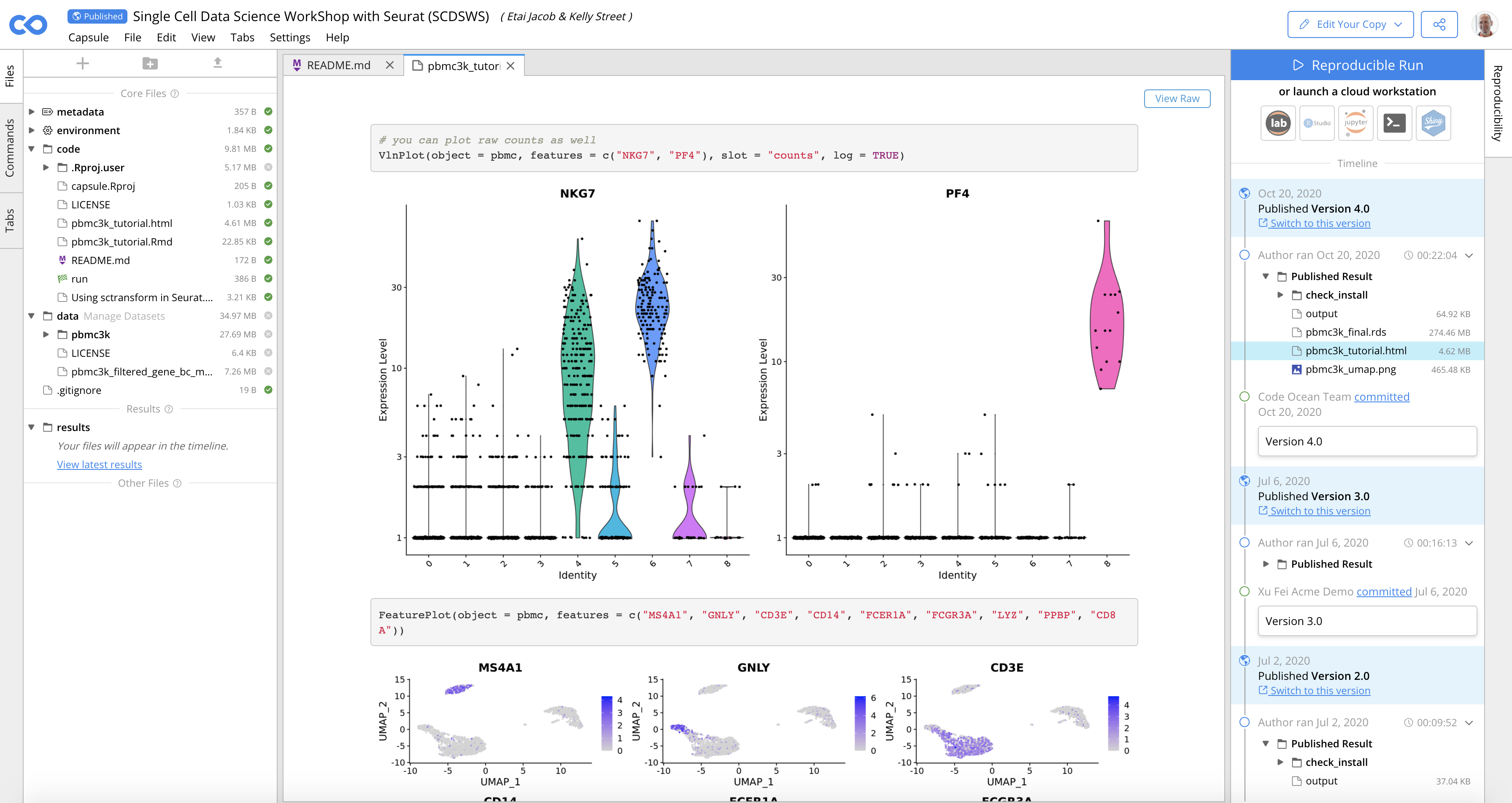
Image Credits: Code Ocean
This sort of cross-pollination of research techniques is as old as science, but modern data-heavy experimentation often ends up siloed because it can’t easily be shared and verified even though the code is technically available. That means other researchers move on, build their own thing, and further reinforce the silo system.
Right now there are about 2,000 public compute capsules on Code Ocean, most of which are associated with a published paper. Most have also been used by others, either to replicate or try something new, and some, like ultra-specific open source code libraries, have been used by thousands.
Naturally there are security concerns when working with proprietary or medically sensitive data, and the enterprise product allows the whole system to run on a private cloud platform. That way it would be more of an internal tool, and at major research institutions that in itself could be quite useful.
Code Ocean hopes that by being as inclusive as possible in terms of codebases, platforms, compute services and so on will make for a more collaborative environment at the cutting edge.
Clearly that ambition is shared by others, as the the company has raised $21M so far, $6M of which was in previously undisclosed investments and $15M in an A round announced today. The A round was led by Battery Ventures, with Digitalis Ventures, EBSCO, and Vaal Partners participating as well as numerous others.
The money will allow the company to further develop, scale, and promote its platform. With luck they’ll soon find themselves among the rarefied air often breathed by this sort of savvy SaaS — necessary, deeply integrated, and profitable.

